|
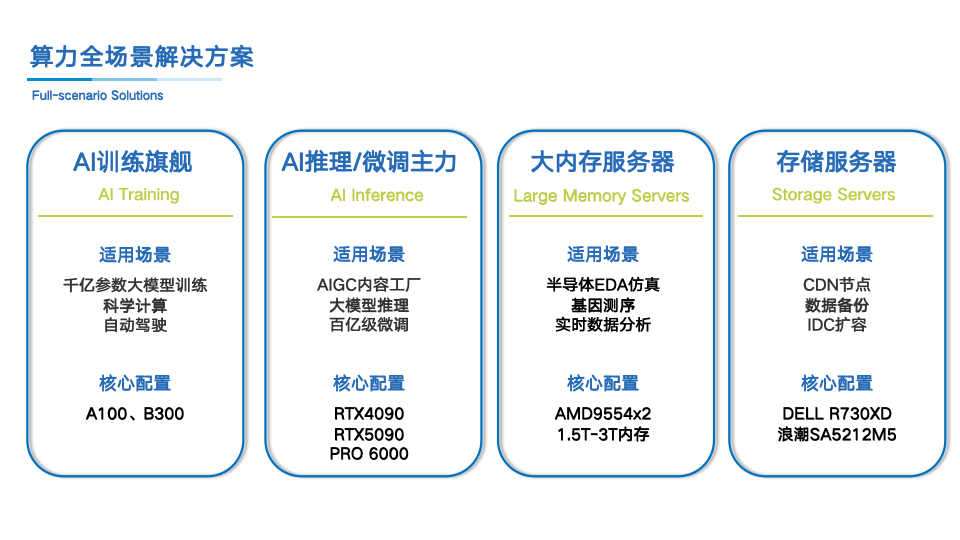
AI研发初创团队的算力困境与破局之道 在人工智能技术快速迭代的当下,AI研发初创团队面临着前所未有的挑战。大模型训练需要强大的算力支撑,推理服务要求高效的GPU资源配置,而数据存储和高性能计算同样不可或缺。然而,动辄数百万的硬件采购成本、3-6个月的设备采购周期、快速的技术更新换代,以及专业运维团队的高昂人力成本,让许多初创团队在技术创新的起点就面临资金与资源的双重压力。 传统的硬件采购模式要求企业一次性投入大量资金,不只占用宝贵的现金流,还面临设备闲置和折旧风险。当项目需求波动时,固定资产难以灵活调配;当新一代硬件发布时,已购设备迅速贬值。对于需要快速验证技术方向、敏捷响应市场需求的AI初创团队而言,这种重资产模式显然不符合其发展节奏。 算力租赁:从资产负担到灵活配置 算力租赁服务的出现,为AI研发团队提供了全新的资源获取路径。这种模式将硬件基础设施的所有权与使用权分离,企业无需承担高额的采购成本和运维压力,即可获得所需的计算资源。小熊U租作为算力基础设施租赁服务商,提供覆盖通用存储、大内存计算、推理算力、训练算力四大类的完整解决方案。 这种服务模式的价值在于其灵活性与可扩展性。零押金的租赁门槛降低了初创团队的启动成本,一天起租的灵活周期适配不同阶段的项目需求,硬件运维全包的服务承诺则让技术团队专注于算法研发而非设备维护。对于业务覆盖北上广深、成都、武汉、南京、厦门、杭州等关键城市的企业,2小时响应的本地化服务能力确保了设备故障时的快速恢复。 场景化算力方案:精细匹配研发需求 AI初创团队的算力需求呈现明显的场景化特征。在模型训练阶段,团队需要强大的并行计算能力来处理海量数据;在推理部署阶段,则更关注性价比与并发响应能力;而数据预处理和存储环节,对容量与传输速度有特定要求。 训练算力场景
对于需要进行大规模模型训练的团队,宁畅6U GPU服务器搭载8张A100 80G GPU,提供312 TFLOPS的FP16稠密算力。这种配置能够支持千亿级参数模型的微调训练,配合10G电口和25G光口的网络设计,确保多节点训练时的高速数据交换。A100基于Ampere架构,80GB的大显存容量允许加载更大的batch size,缩短训练迭代周期。 对于追求前沿算力的研究团队,技嘉G894-SD3-AAX7搭载B300 SXM6 GPU,单卡提供3,500 TFLOPS的FP16算力和7,000 TFLOPS的FP8算力,配合288GB显存和800Gb InfiniBand高速网络,适配万亿参数大模型的预训练任务。这种配置的算力密度达到专业研究机构水平,配合2TB系统内存,可承载极高复杂度的并行计算任务。 推理算力场景
推理服务对算力的需求特点是高并发、低延迟。H3C 5300G5或联想系列服务器搭载8张RTX 4090 24G或RTX 5090 32G显卡,为AIGC内容生成提供经济高效的方案。RTX 4090基于Ada Lovelace架构,165 TFLOPS的FP16算力配合330 TFLOPS的FP8算力,在智能客服、AI绘画、视频生成等场景中展现出色的性价比。RTX 5090采用Blackwell架构,419 TFLOPS的FP16算力和838 TFLOPS的FP8算力,32GB显存容量提升了大模型推理的承载能力。 对于需要超大显存的专业推理场景,同泰怡TG658V3搭载8张RTX PRO 6000 96G显卡,单机总显存达到768GB。这种配置适合复杂场景下的高精度AI内容生成,单卡504 TFLOPS的FP16算力和1,008 TFLOPS的FP8算力,配合96GB显存,可同时加载多个模型或处理超高分辨率内容生成任务。 大内存计算场景 半导体EDA仿真、大规模虚拟化、内存数据库等应用场景,对内存容量有极高要求。曙光2U AMD平台搭载双路AMD 7763处理器,提供128核256线程的并行计算能力,配合2TB DDR4内存,可将TB级数据集完全加载至内存运算。这种配置在芯片电路仿真中能够大幅减少磁盘I/O等待时间,提升仿真效率。配合25G双光口网络,支持高速数据交换。 超聚变2288H V6或2258 V7系列采用Intel 8368Q或AMD 9554处理器,支持1.5TB至3TB DDR4/DDR5内存扩展。这种配置适配SAP HANA等内存数据库和大型企业关键系统,高频率内存配合新一代处理器平台,满足金融风险建模和工业仿真的高稳定性需求。 通用存储场景 AI训练和推理产生的海量数据需要可靠的存储方案。DELL R730XD配备双路E5-2680 v4处理器(28核56线程)和128GB DDR4内存,支持12块3.5英寸热插拔HDD扩展,配合960GB SSD系统盘,为中小规模CDN节点、企业文件服务器和备份归档提供高性价比存储容量。 浪潮SA5212M5采用双路专门8163处理器(48核96线程)和256GB DDR4内存,配置960GB SSD和10TB HDD的混合存储架构,结合10G光口网络,在数据库存储和高性能存储池场景中提供计算与存储的均衡性能。这种配置适合需要频繁数据读写的虚拟化环境和分布式存储系统。 选型决策:匹配业务发展阶段 AI初创团队在选择算力方案时,需要综合考虑应用场景、规模需求和成本预算。首先明确应用场景是AI训练、推理、通用IT还是EDA仿真;其次根据模型参数量(从7B到万亿级)、并发量和内存需求(1TB-6TB)匹配对应机型;然后按照存储优先选DELL或浪潮、内存优先选超聚变或曙光、算力优先选同泰怡或宁畅或技嘉的资源匹配原则进行选型。 租期方案的灵活性同样关键。短期测试(2周)适合技术验证和POC阶段,中期项目(1-6个月)匹配特定项目周期,长期稳定(12个月及以上)则适合持续性业务需求。这种按需租赁的模式,让初创团队可以根据业务发展动态调整资源配置,避免资源浪费和资金占用。 轻资产模式的战略价值 对于AI研发初创团队而言,算力租赁不只是成本优化手段,更是战略资源配置方式。通过将硬件基础设施从资本支出转为运营支出,团队可以将有限的资金投入到算法研发、人才引进和市场拓展等重要业务中。本地化部署或托管至合作数据中心的灵活交付模式,适配不同企业的数据安全和运维管理需求。 硬件运维全包的服务模式,让技术团队摆脱设备故障排查、固件升级、性能调优等繁琐事务。在关键城市提供的2小时响应支持,确保业务连续性不受硬件故障影响。这种专业化分工,让初创团队以更轻的资产结构、更快的响应速度,在AI技术浪潮中把握创新机遇。 算力基础设施的租赁模式,正在重塑AI初创团队的资源获取方式。从重资产采购到轻资产租赁,从设备运维到专注研发,从固定配置到弹性扩展,这种转变让技术创新的门槛大幅降低,为更多AI研发团队提供了参与行业竞争的可能性。
| 

 |Archiver|CAD开发者社区
( 苏ICP备2022047690号-1 苏公网安备32011402011833)
|Archiver|CAD开发者社区
( 苏ICP备2022047690号-1 苏公网安备32011402011833)




 发表于
发表于